Hive Partitioning Layout
A self-documenting schema for your data

Lakehouse design is one of my favorites because it gives us the best of two worlds. In a data warehouse, we can manage and transform data easily. It can be a single source of truth for all data transformations we do. Whereas in a data lake, we can use multiple partitions, scale more efficiently and process large amounts of very big data cheaper.
What is a Hive partitioning layout?
Very often I would want to store data in cloud storage and it would be better to have a self-documented schema for each table there. We can achieve this by using the default Hive partitioning layout. Consider this example:
gs://events-export-avro/public-project/avro_external_test/dt=2018-10-01/lang=en/partitionKey
gs://events-export-avro/public-project/avro_external_test/dt=2018-10-02/lang=fr/partitionKey
By just examining the file locations, you can certainly infer that the data is divided into sections according to day and nation.
So Hive layout assumes the following:
instead of
YYYY/MM/DDwe will usekey = valuepairs which will be partitioning columns and storage folders at the same timepartition keys are always in the same order
This is also a Hive partitioning layout:
some_table_in_storage/day=2023-06-20/country=fr/742c.json
some_table_in_storage/day=2023-06-20/country=ir/7e0c.json
This is definitely not a bad schema convention to follow, and many tools in the Hadoop ecosystem are aware of it.
Our natural human way of organizing that table would be something like this:
data/2023-04-21/us/2b83.json
This is not too bad but Hive tools won't be able to use it directly. In this case, we would want to use some extra tool, i.e. AWS Glue Crawler to read the schema and translate it for Athena. Crawler is a great tool to autodetect the schema.
However, Athena can do both if we tell it how to load the data. We can add new partitions with ease by using the ALTER TABLE ADD PARTITION query for both Hive style and non-Hive style format data:
ALTER TABLE some-example-table ADD
PARTITION (year='2023', month='01', day='01') LOCATION 's3://some-example-bucket/example-folder/2023/01/01/'
PARTITION (year='2023', month='06', day='01') LOCATION 's3://some-example-bucket/example-folder/2020/06/01/'
If we have data in S3 stored in Hive style then it makes it even easier to load the new partitions into Athena by using the MSCK REPAIR TABLE:
MSCK REPAIR TABLE some-example-table
Our data just must be stored in S3.
Create an external table
Let's create an external table in AWS Athena as an example.
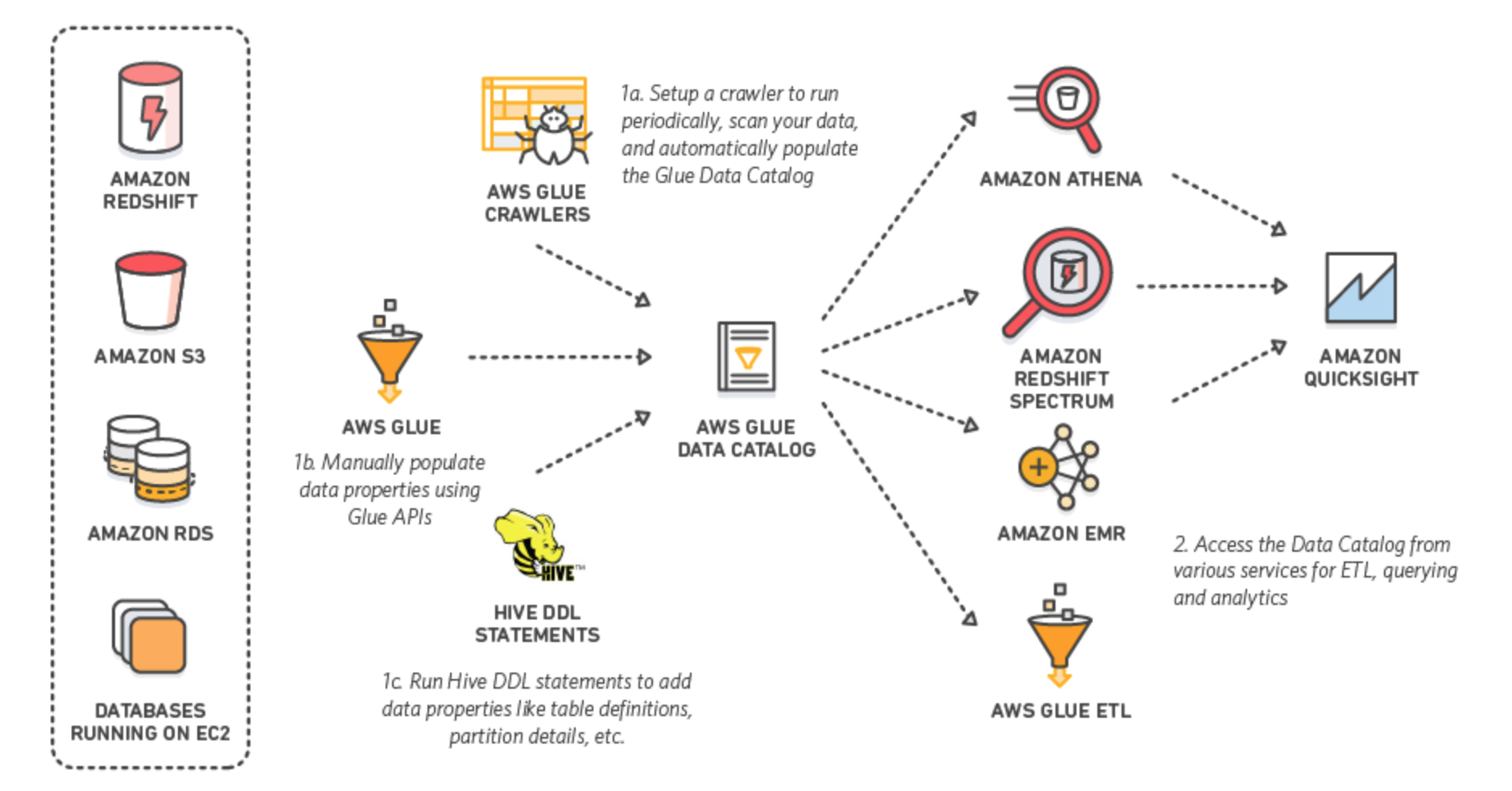

Athena uses Apache Hive to define tables and create databases. Tables in Athena can be created by using these tools:
AWS Glue Crawler. It will crawl through our data files and read schema information, i.e. columns and partitioning.
Schema can be also defined with Infrastructure as Code (AWS Cloudformation) or manually when we create a table in the AWS console.
Using SQL DDL:
CREATE EXTERNAL TABLE users (
first string,
last string,
username string
)
PARTITIONED BY (id string)
STORED AS parquet
LOCATION 's3://SOME-EXAMPLE-BUCKET/folder/'
A few things to consider:
Partitions work great in Athena and specifying them in
WHEREclause can help to reduce costs related to queries.Athena WILL NOT filter the partition and instead reads all of the data from the partitioned table if the partition name appears in the subquery's WHERE clause.
MSCK REPAIR TABLEdoesn't like the camel case, i.e. if our file keys areuserIdinstead ofuseridthen new partitions will not be added.MSCK REPAIR TABLEscans both folder and subfolder. To avoid mixing up the partitions from different tables use separate folder structures, i.e. s3://table-one-data and s3://table-two-data.Athena supports querying AWS Glue tables that have 10 million partitions, Athena cannot read more than 1 million partitions in a single scan.
In Athena DDL queries and partition detection are free.
A really good practice for syncing partitions is to use
alter tablestatement.MSCK REPAIR TABLEmight become very slow if we have too many partitions.
Hive partitioning layout and other data solutions
Many data solutions understand Hive layout. Starburst Galaxy is one of Athena's rivals and it also has a Hive connector
Other Hadoop ecosystem tools have no problem with understanding the Hive partitioning layout and reading the schema if we don't explicitly describe it.
A good example is Google BigQuery. It is a data warehouse and in BigQuery we can create external tables even if we don't know the schema and columns:
CREATE OR REPLACE EXTERNAL TABLE source.custom_hive_partitioned_table
WITH PARTITION COLUMNS (
dt STRING, -- column order must match the external path
lang STRING)
OPTIONS (
uris = ['gs://events-export-avro/public-project/avro_external_test/*'],
format = 'AVRO',
hive_partition_uri_prefix = 'gs://events-export-avro/public-project/avro_external_test',
require_hive_partition_filter = false);
I am using AVRO file format here which would be a good choice for any data lake landing area. If you want to learn more about pros and cons of AVRO, Aprquet and ORC there is another article here:
https://towardsdatascience.com/big-data-file-formats-explained-275876dc1fc9
We can connect various data sources in different cloud platforms using this pattern. I previously wrote about how to extract data from BigQuery to store it with Hive style layout:
Conclusion
Organizing our data lake this self-documenting way makes data available for many other tools in the Hadoop world. In this case, we can also create externally partitioned tables on Avro, CSV, JSON, ORC and Parquet files with ease. It can be easily loaded even into our data warehouse solution if we need it. Being products of the Hadoop ecosystem that heavily rely on Hive's code, data solutions like Starburst Galaxy, Athena and Glue are aware of and efficient at utilizing the Hive partitioning layout.
Recommended read:
1. https://aws.amazon.com/glue/pricing/
3. https://docs.aws.amazon.com/athena/latest/ug/create-table.html
4. https://docs.starburst.io/latest/connector/hive.html
6. https://aws.amazon.com/premiumsupport/knowledge-center/athena-create-use-partitioned-tables/
7. https://docs.aws.amazon.com/athena/latest/ug/partitions.html
8. https://repost.aws/questions/QUDcQff8BKR5Sg4W1NzYdZFg/cost-of-athena-and-glue
9. https://repost.aws/questions/QUDcQff8BKR5Sg4W1NzYdZFg/cost-of-athena-and-glue


