Data Platform Architecture Types
How well does it answer your business needs? Dilemma of a choice.

It is easy to get lost with the abundance of data tools available in the market right now. The Internet is filled with opinionated stories (often speculative) about which data tools to use and how to make our Data Stack modern in this particular year.
So what is a "Modern Data Stack" and how modern is it?
To put it simply, it is a collection of tools used to work with data. Depending on what we are going to do with the data, these tools might include the following:
- a managed ETL/ELT data pipeline services
- a cloud-based managed data warehouse/ data lake as a destination for data
- a data transformation tool
- a business intelligence or data visualization platform
- machine learning and data science capabilities
Sometimes it doesn't matter how modern it is.
Indeed, if our BI tool is super modern with bespoke OLAP cubes for data modelling and git integration but it can't render a report into an email.
Often these little things matter. Business needs and data pipeline requirements are the most important.
In the diagram below we can see the data journey and a selection of relevant tools to use during each step of the data pipeline.
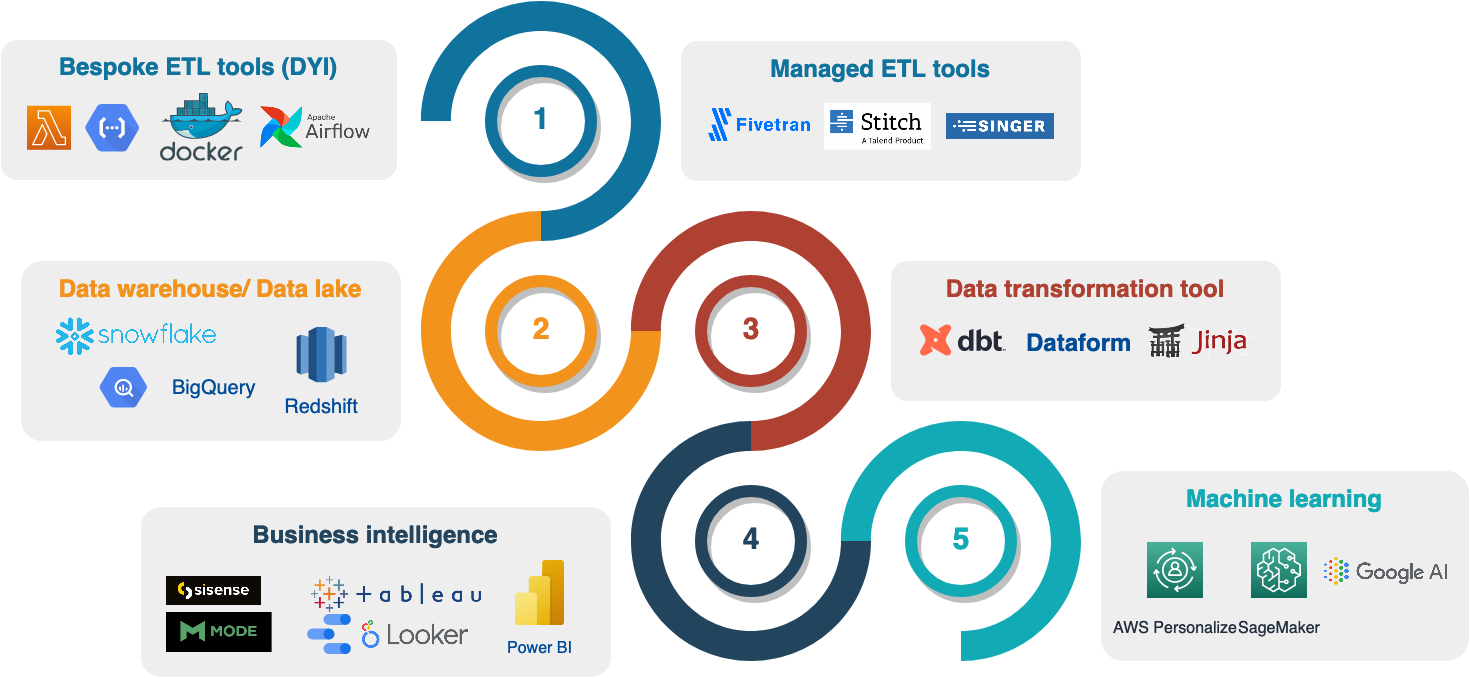
Redshift, Postgres, Google BigQuery, Snowflake, Databricks, Hadoop, Dataproc, Spark, or Elastic Map Reduce?
Which product to choose for your data platform?
It depends on the daily tasks you are planning to run with your data, Data Processing and Data Storage Architecture, which suits these tasks the most.
Data platform architecture types
I remember a couple of years ago the internet was boiling with "Hasdoop is dead" type stories. There was a noticeable shift toward data warehousing architecture. In 2023 everyone seems to be obsessed with real-time data streaming and scalability suggesting Spark and Kafka soon become the public benchmark leaders.
So which one is the best? Who is the leader and which tools to choose?
What I understood is that those benchmark judgments were very subjective and should have been considered with a pinch of salt. What matters is how well those tools are aligned with our business requirements should we wish to build a data platform.
Data warehouse
A serverless, distributed SQL engine (BigQuery, Snowflake, Redshift, Microsoft Azure Synapse, Teradata.). It is a SQL-first data architecture where your data is stored in a data warehouse and you are free to use all the advantages of using denormalized star schema datasets. Of course, we can do it because most of the modern data warehouses are distributed and scale well, which means you don't need to worry about table keys and indices. It suits well for ad-hoc analytics working with Big Data.
Most of the modern data warehouse solutions can process structured and unstructured data and are indeed very convenient if the majority of your users are data analysts with good SQL skills. Modern data warehouses integrate easily with Business intelligence solutions like Looker, Tableau, Sisense, or Mode, which also rely on ANSI-SQL a lot. It is not designed to store images, videos, or documents. However, with SQL you can do almost everything and even train Machine learning models in some vendor solutions.
https://medium.com/towards-data-science/advanced-sql-techniques-for-beginners-211851a28488
Data lake (Databricks, Dataproc, EMR)
A type of architecture where your data is being stored in the cloud storage, i.e., AWS S3, Google Cloud Storage, ABS. It is, of course, natural to use it for images, videos, or documents as well as any other file types (JSON, CSV, PARQUET, AVRO, etc.), but to analyze it your users will have to write some code.
The most common programming language for this task would be Python with a good number of libraries available. JAVA, Scala, or PySpark would be another popular choice for this task.
Amazing benefits come with code.
It is the highest level of flexibility in data processing. Our users just need to know how to do it.
Lakehouse
A combination of data warehouse and data lake architecture. It has the best of two worlds and serves both programmers and regular business users such as data analysts. It enables your business with the ability to run interactive SQL queries while remaining very flexible in terms of customization. Most of the modern data warehouse solutions can run interactive queries on data that is stored in the data lake, i.e. external tables. One data pipeline can look like this, for example:
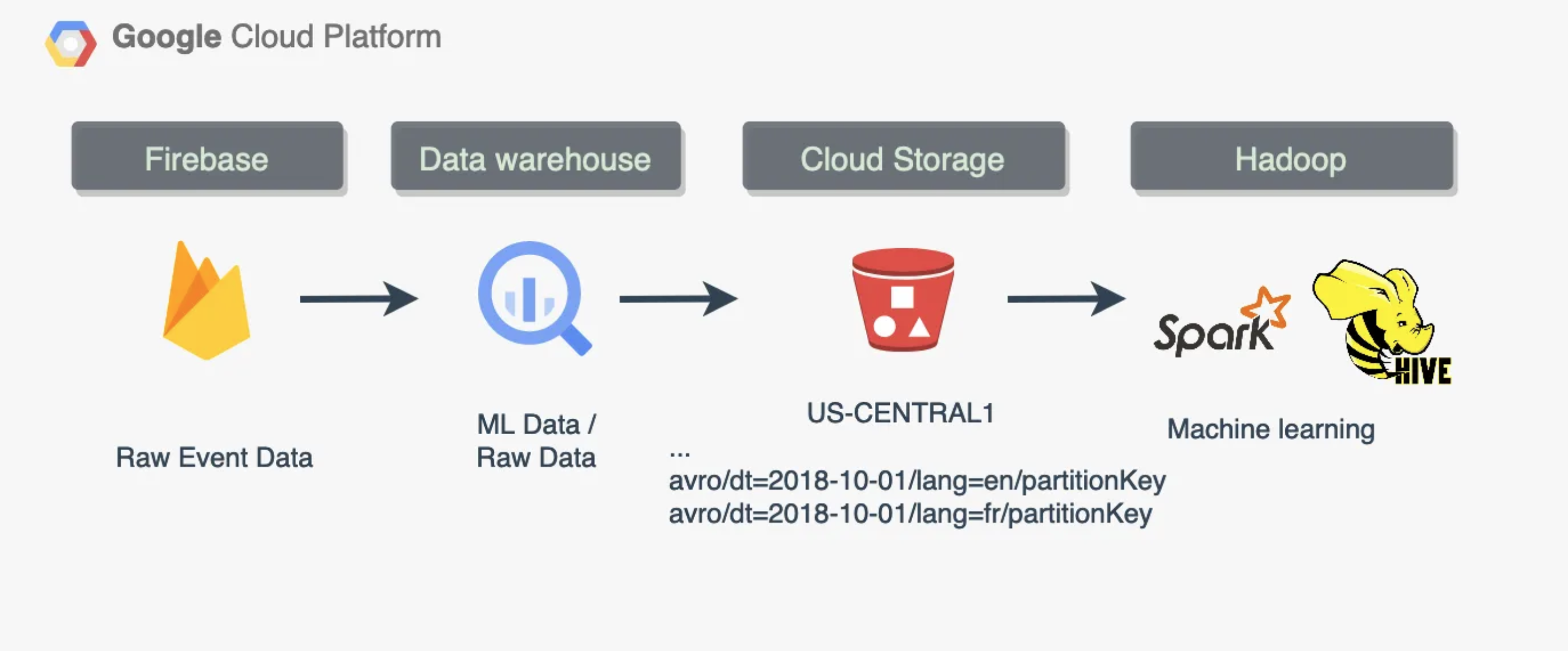
I wrote about it before.
Data mesh
A data mesh architecture is a decentralized approach that enables your company to manage data and run cross-team / cross-domain data analysis on its own and share the data.
Each business unit might have a mix of different programming skills, i.e. SQL or Python as well as a variety of data workload requirements (flexible data processing vs. interaction SQL queries). Having said that, each business unit is free to choose its own data warehouse/data lake solution but still will be able to share the data with other units with no data movement.
Relational and Non-relational Database Management systems
A Relational Database Management system (RDS) stores data in a row-based table with columns that connect related data elements. It is designed to record and optimize to fetch current data quickly. Popular relational databases are PostgreSQL, MySQL, Microsoft SQL Server, and Oracle. NoSQL databases don't support only simple transactions, whereas Relational Database also supports complex transactions with joins. NoSQL Database is used to handle data coming at high velocity. Popular NoSQL databases are:
Document databases: MongoDB and CouchDB
Key-value databases: Redis and DynamoDB
A data warehouse has a similar columnar structure, same as RDS it is relational. Data is organized into tables, rows, and columns too. However, it is different in the way that database data is organized and stored by row, while data warehouse data is stored by columns, to facilitate online analytical processing (OLAP) whereas database uses Online Transactional Processing (OLTP). For example, AWS Redshift supports both data warehouse and data lake approaches, enabling it to access and analyze large amounts of data.
A Data warehouse is designed for data analysis, including large amounts of historical data. Using a data warehouse require users to create a pre-defined, fixed schema upfront, which helps with data analytics a lot. Tables must be simple (denormalized) to compute large amounts of data.
RDS database tables and joins are complicated because they are normalised. So the primary difference between a traditional database and a data warehouse is that while the traditional database is designed and optimized to record data, the data warehouse is designed and optimized to respond to analytics. You would want to use a database when you run an App and you need to fetch some current data fast. RDS stores the current data required to power an application.
You will have to decide which one is right for you.
Business intelligence stack
Modern Data Stack should include BI tools that help with data modelling and visualization. Some high-level overviews can be found below. Not an extensive list, of course, but these are the most popular BI tools available in the market as of 2023:
Looker Data Studio (Google Looker Studio)
Key features:
Free version formerly called Google Data Studio. This is a great free tool for BI with community-based support.
Great collection of widgets and charts
Great collection of community-based data connectors
Free email scheduling and delivery. Perfectly renders reports into an email.
Free data governance features
As it's a free community tool it has a bit of undeveloped API
Looker (paid version)
Key features:
Robust data modelling features and self-serving capabilities. Great for medium and large size companies.
API features
Tableau
Key features:
Outstanding visuals
Reasonable pricing
Patented VizQL engine driving its intuitive analytics experience
Connections with many data sources, such as HADOOP, SAP, and DB Technologies, improving data analytics quality.
Integrations with Slack, Salesforce, and many others.
AWS Quicksight
Key features:
Custom-branded email reports
Serverless and easy to manage
Robust API
Serverless auto-scaling
Pay-per-use pricing
Power BI
Key features:
Excel integration
Powerful data ingestion and connection capabilities
Shared dashboards from Excel data made with ease
A range of visuals and graphics is readily available
Sisense (former Periscope)
Sisense is an end-to-end data analytics platform that makes data discovery and analytics accessible to customers and employees alike via an embeddable, scalable architecture.
Key features:
Offers data connectors for almost every major service and data source
Delivers a code-free experience for non-technical users, though the platform also supports Python, R, and SQL
Git integration and custom datasets
Might be a bit expensive as it's based on pay per license per user model
Some features are still under construction, i.e. report email delivery and report rendering
ThoughtSpot
Key features:
- Natural language for queries
Mode
Key features:
CSS design for dashboards
Collaboration features to allow rapid prototyping before committing to a premium plan
Notebook support
Git support
Metabase
Key features:
Great for beginners and very flexible
Has a docker image so we can run it straight away
Self-service Analytics
Redash
Key features:
API
Write queries in their natural syntax and explore schemas
Use query results as data sources to join different databases
Some of these tools have free versions. For example, Looker Data Studio is free with basic dashboarding features like email, i.e. drag-and-drop widget builder, and a good selection of charts. Others have paid features, i.e., data modelling, alerts, notebooks, and git integration.
They are all great tools with their pros and cons. Some of them are more user-friendly some can offer more robust APIs, CI/CD features, and git integration. For some of the tools, these features are available only in the paid version.
Conclusion
Modern data-driven apps will require a database to store the current application data. So if you have an application to run, consider OLTP and RDS architecture.
Data lakes, warehouses, lake houses, and databases each have their benefits and serve each purpose.
Companies that want to perform big data analytics running complex SQL queries on historical data may choose to complement their databases with a data warehouse (or a lake house). It makes the data stack flexible and modern.
In general, the answer would always be the same:
Go for the cheapest one or the one that works best with your dev stack
Try it and you will see that a relational database can be easily integrated into the data platform. It doesn't matter if it's a data lake or a data warehouse. A variety of data connectors will enable easy and seamless data extraction. You can even try a bespoke one:
However, there are a few things to consider.
The key thing here is to try data tools to see how well they can be aligned with our business requirements.
For example, some BI tools can offer only pay-per-user pricing which won't be a good fit in case we need to share the dashboard with external users.
If there are any cost-saving benefits it might be better to keep data tools with the same cloud vendor where your development stack is.
We might want to check if there is an overlap in functionality between tools, i.e. do we really need a BI solution that would perform data modelling in its own OLAP cube when we already do it in the data warehouse?
Data modelling is important
Indeed, it defines how often we process the data which will inevitably reflect in processing costs.
The shift to a lake or data warehouse would depend primarily on the skillset of your users. The Data warehouse solution will enable more interactivity and narrows down our choice to a SQL-first product (Snowflake, BigQuery, etc.).
Data lakes are for users with programming skills and we would want to go for Python-first products like Databricks, Galaxy, Dataproc, EMR.


