Big Data File Formats Explained
Parquet vs ORC vs AVRO vs JSON

Which one to choose and how to use them? All you should know about it including performance tips.
I'm a big fan of data warehouse (DWH) solutions with ELT-designed (Extract-Load-Transform) data pipelines. However, at some point, I faced the requirement to unload some huge amounts of historical raw event data into the Cloud Storage and had to choose the file format for data files.
The requirement was simple and emphasized the idea of reducing the costs related to data storage in the data warehouse.
I created an archive bucket that would be the cheapest storage class and prepared to extract the data from some really big tables I had in my DWH. I have to say, those tables were heavy and contained a lot of raw events with user engagement data. Therefore, they were the most expensive storage part of the whole data platform.
This is a typical scenario when machine learning engineers are tasked to create behavior datasets to provide better product recommendations or predict customer churn.
And then I had to stop at some point to make a decision on which file format to use because storage size wasn't the only consideration.
Indeed, in some scenarios read/write time or better schema support might be more important
Parquet vs ORC vs AVRO vs JSON
With the rise of Data Mesh and a considerable number of data processing tools available in the Hadoop eco-system, it might be more effective to process raw event data in the data lake.
Modern data warehouse solutions are great but some pricing models are more expensive than the others
One of the greatest benefits of big data file formats is that they carry schema information on board. Therefore, it is much easier to load data in, split the data to process it more efficiently, etc. JSON can't offer that feature and we would want to define the schema each time we read, load or validate the data.
Columnar ORC and Parquet
Parquet is a column-oriented data storage format designed for the Apache Hadoop ecosystem (backed by Cloudera, in collaboration with Twitter). It is very popular among data scientists and data engineers working with Spark. When working with huge amounts of data, you start to notice the major advantage of columnar data, which is achieved when a table has many more rows than columns.

Parquet File Layout. Source: apache.org
Spark scales well and that's why everybody likes it
In fact, Parquet is a default data file format for Spark. Parquet performs beautifully while querying and working with analytical workloads.
Columnar formats are more suitable for OLAP analytical queries. Specifically, we would want to retrieve only the column we need to perform an analytical query. That definitely has certain implications on memory and therefore, on performance and speed.
ORC (Optimised Row Columnar) is also a column-oriented data storage format similar to Parquet which carries a schema on board. it means that like Parquet it is self-describing and we can use it to load data into different disks or nodes.
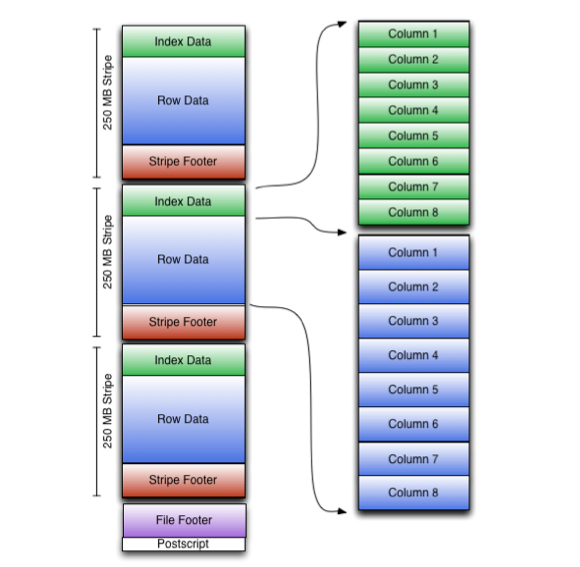
ORC file layout. Source: apache.org
I did a little test and it seems that both Parquet and ORC offer similar compression ratios. However, there is an opinion that ORC is more compression efficient.
10 Mb compressed with SNAPPY algorithm will turn into 2.4Mb in Parquet
However, I have a feeling that ORC is supported by a smaller number of Hadoop projects than Parquet, i.e. Hive and Pig.
So if we want a wider range of tools to run our OLAP analytics in the data lake I would recommend using Parquet. It has wider project support and especially Spark.
In reality, PARQUET and ORC have somewhat different columnar architecture.
Both work really well saving you a great deal of disk space.
However, data in ORC files are organized into independent stripes of data. Each has its own separate index, row data, and footer. It enables large, efficient reads from HDFS, making this format.
The data is stored as pages in Parquet, and each page includes header information, definition level information, and repetition level information.
It is very effective when it comes to supporting a complicated nested data structure and seems to be more efficient at performing IO-type operations on data. The great advantage here is that read time can be significantly decreased if we choose only the columns we need.
My personal experience suggests that selecting just a few columns would typically read the data up to 30 times (!) faster than reading the same file with the complete schema. Other tests performed by data engineers confirm that finding.
Long story short, choose ORC if you work on HIVE. It is better optimized for it. And Choose Parquet if you work with Spark as that would be the default storage format for it.
In everything else, both ORC and Parquet share similar architecture and KPIs look roughly the same.
AVRO
AVRO is a row-based storage format where data is indexed to improve query performance.
It defines data types and schemas using JSON data and stores the data in a binary format (condensed) that help with disk space.
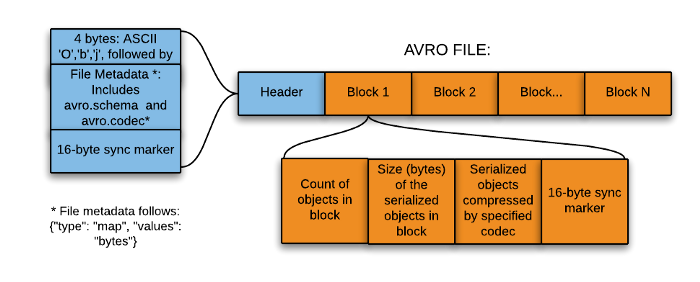
avro file structure. Source: apache.org
Compared to Parquet and ORC it seems that it offers less efficient compression but faster write speeds.
10 Mb Parquet compressed with SNAPPY algorithm will turn into 2.4Mb in Parquet
10 Mb AVRO compressed with SNAPPY algorithm will turn into 6.2Mb
The same 10 Mb AVRO compressed with DEFLATE algorithm will require 4Mb of storage
The main advantage of AVRO is schema-evolution support. In other words, as data schemas evolve over time, AVRO enables those changes by tolerating fields that have been added, removed, or altered.
Avro works really well with things like added fields and changed fields, missing fields.
AVRO is more efficient while working with write-intensive, big-data operations.
It is a great candidate to store data in source layer or a landing area of our data platform because these f**iles are usually being read as a whole for further transformation depending on the data pipeline. Any schema evolution changes are handled with ease.
https://docs.google.com/spreadsheets/d/1UoCRx2YZRuh-uu7Cajp37RLcW1E7iXoVFX3sKAL2ouw/edit#gid=0
Even applications written in different languages can share data saved using Avro. Data exchange services might require a coding generator to decipher data specifications and generate code to access data. AVRO is an ideal contender for scripting languages because it doesn't require this.
JSON
For online applications, structured data is frequently serialized and sent using the JavaScript Object Notation (JSON) format.
This implies that a significant portion of the big data is gathered and kept in a JSON format.
However, because JSON is not highly typed nor schema-enriched, dealing with JSON files in big data technologies like Hadoop may be sluggish.
Basically, it's a no-go for Big Data processing frameworks. This is the main reason Parquet and ORC formats were created.
Compression
How does it work?
A quick answer is to choose splittable compression types if our primary objective is to gain data processing performance, and non-splittable like GZIP, DEFLATE if storage costs deduction is our main objective.
What is splittable?
Splittable means that Hadoop Mapper can split or divide a large file and process it in parallel. Compressing codecs apply compression in blocks and when it is applied at the block level mappers can read a single file concurrently even if it is a very large file.
Having said that, splittable compression types are LZO, LZ4, BZIP2 and SNAPPY whereas GZIP isn't. These are very fast compressors and very fast decompressors. So if we can tolerate bigger storage then it is a better choice than GZIP.
GZIP on average has a 30% better compression rate and would be a good choice for data that doesn't require frequent access (cold storage).
External data in lakes and Data warehouse
Can we query external data storage using a data warehouse?
Typically, all modern data warehouses offer externally partitioned table features so we can run analytics on data lake data.
There is a number of limitation of course but in general, it is enough to connect two worlds in order to understand how it works.
For example, in BigQuery we can create an external table in our data warehouse like so:
CREATE OR REPLACE EXTERNAL TABLE source.parquet_external_test OPTIONS (
format = 'PARQUET',
uris = ['gs://events-export-parquet/public-project/events-*']
);
select * from source.parquet_external_test;
You will notice that external tables are much slower in any DWH and are limited in many ways, i.e. limited concurrent queries, no DML and wildcard support and inconsistency if underlying data was changed during the query run.
So we might want to load it back like so:
LOAD DATA INTO source.parquet_external_test
FROM FILES(
format='PARQUET',
uris = ['gs://events-export-parquet/*']
)
Native tables are faster.
If there is another data processing tool, then we might want to use a Hive partition layout. This is usually required to enable external partitioning. i.e.
gs://events-export-parquet/public-project/parquet_external_test/dt=2018-10-01/lang=en/partitionKey
gs://events-export-parquet/public-project/parquet_external_test/dt=2018-10-02/lang=fr/partitionKey
Here partition keys have to be always in the same order. And for partitioning, we will use key = value pairs which will be storage folders at the same time.
We can use it in any other data processing framework that supports HIVE layout.
https://mydataschool.com/blog/hive-partitioning-layout/
Conclusion
If we need support for Spark and a flat columnar format with efficient querying of complex nested data structures then we should use Parquet. It is highly integrated with Apache Spark and is, actually, a default file format for this framework.
If our data platform architecture relies on data pipelines built with Hive or Pig then ORC data format is the better choice. Having all the advantages of columnar format it performs beautifully in analytical data lake queries but is better integrated with Hive and Pig. Therefore, the performance might be better compared to Parquet.
When we need a higher compression ratio and faster read times then Parquet or ORC would suit better. Compared to AVRO read times might be up to 3 times faster. It can be improved even further if we reduce the number of selected columns to read.
However, we don't worry too much about the speed of input operations AVRO might be a better choice offering a reasonable compression with splittable SNAPPY, schema evolution support and way faster write speed (it is row-based remember?). AVRO is an absolute leader in write-intensive, big-data operations. Therefore, it suits better for storing the data in the source layer of our data platform.
GZIP, DEFLATE and other non-splittable compression types would work best for cold storage where frequent access to data is not required.
Recommended read
1. https://cwiki.apache.org/confluence/display/hive/languagemanual+orc
2. https://parquet.apache.org/
5. https://avro.apache.org/docs/1.11.1/specification/
6. https://stackoverflow.com/questions/14820450/best-splittable-compression-for-hadoop-input-bz2


