

Photo by Jason Leung on Unsplash
Data Platform Unit and Integration Tests Explained
Beginners guide to testing and data engineering example


What is a unit or integration test?
How to do this exercise and how to apply it to our data pipelines? This is a good question I asked myself at the very beginning of my data engineering career. This topic seemed a bit difficult but believe me, it pays off in the long-term perspective.
Integration and unit testing is a "MUST HAVE" skill for any engineer
Put simply, a unit test is when we task our code in small pieces.
An integration test is when we test how our application interacts with something else, i.e. another service or API.
Let's imagine we are building a data pipeline where some data transformation will be performed by AWS Lambda. It can be anything, i.e. extract operation, data cleansing or PII masking, sending data files between clouds, etc.
I previously wrote about data pipelines here:
https://medium.com/towards-data-science/data-pipeline-design-patterns-100afa4b93e3
Something like that will do the job, it's just an example anyway:

Example data pipeline. Image by author
Our simple microservice is very basic and has only one function processEvent() to return a list of data jobs with runTime attached. app.js looks like this:
/* eslint-disable no-throw-literal */
const moment = require('moment');
exports.handler = async(event, context) => {
console.log('Now: ', moment());
try {
const jobs = event.jobs;
const successfullJobs = await processEvent(jobs);
if (successfullJobs.errorCode) {
throw successfullJobs;
}
// console.log(successfullJobs);
return {
'statusCode': 200,
'data': successfullJobs,
'context': context ? context.succeed() : null,
};
} catch (e) {
return {
'statusCode': 400,
'data': e,
'context': context ? context.done() : null,
};
}
};
const processEvent = async(jobs) => {
const now = moment.utc();
const jobList = [];
for (const job of jobs) {
try {
if (typeof job.name === 'undefined') {
throw { errorCode: 1, message: 'job.name is missing' };
}
const jobTime = now.format('YYYY-MM-DD HH:mm');
jobList.push({
name: job.name,
runTime: jobTime,
});
} catch (error) {
return error;
}
}
return jobList;
};
We already have a few unit tests that will check the following:
Lambda always comes with a response having a
statusCodeAll processed data jobs have a
runTimekey
If you run this in your command line it will perform these tests:
npm run test-unit
And the result would be this:
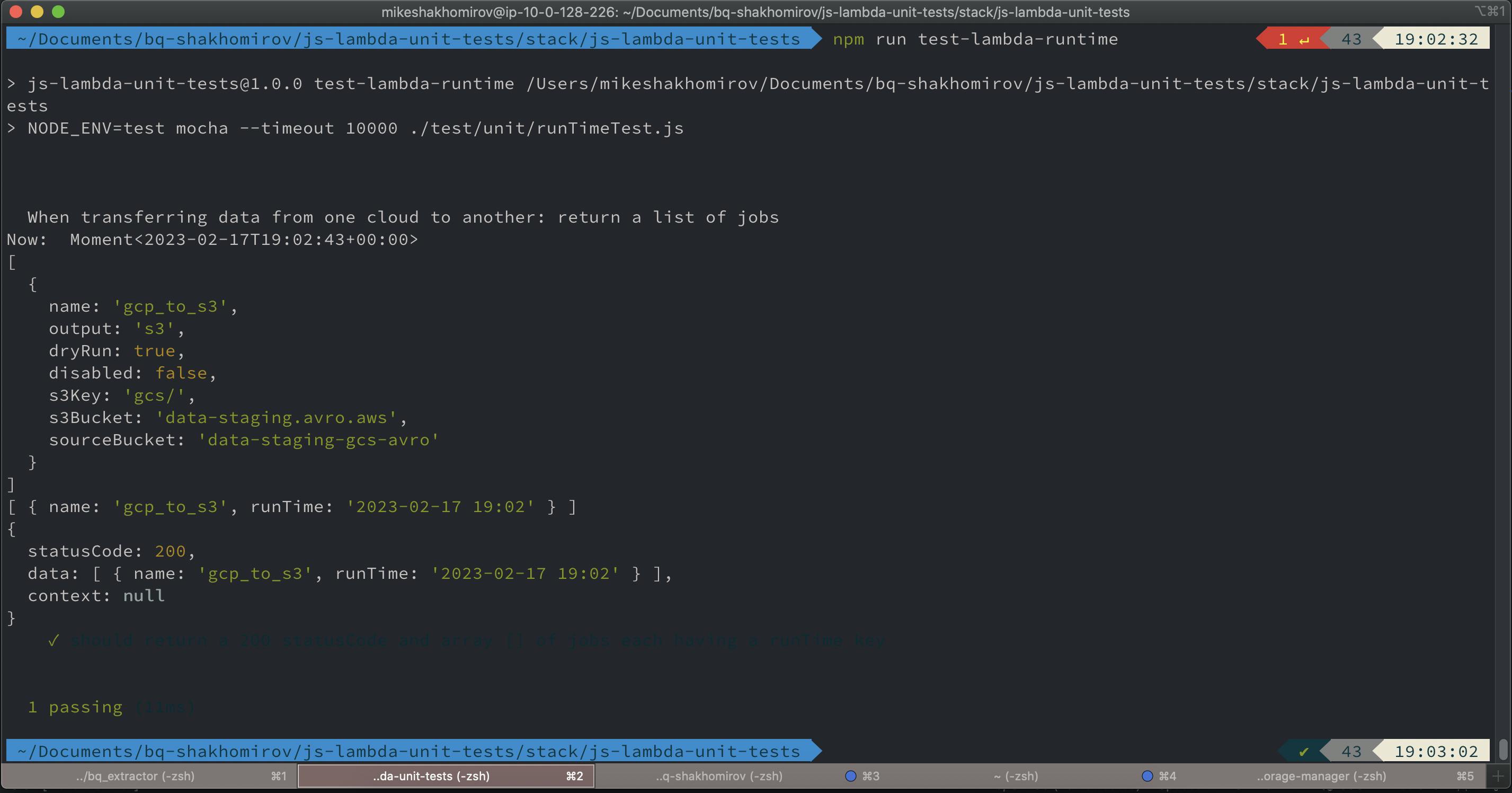
I use the Mocha framework for testing and Chai for assertions and it works beautifully. You will find the links at the end of this story.

Mocha is a fantastic testing framework that allows us to recursively run every test in the test folder.
use of any assertion library (Chai).
asynchronous testing.
test coverage reports.
Mocha and Chai may be used together to raise assertions in our tests. Chai is an assertion library for NodeJS.

Adding an integration test
So what if we need to test connectivity with some other service? It can be one of the services we deploy in VPC or something external, i.e. a data warehouse.
I will use Google BigQuery as an example.
I like BigQuery. It's a great data warehouse where we can control everything including partitions and what's most important - it is free to run smaller queries making it a perfect candidate for our setup.
For example, we might want to test that one of our SQL queries that we use in Lambda actually does the job and logic remains the same always.
We will need the following:
Google Cloud Platform service account to authenticate BigQuery client from our
app.jsAn extra function to run a SQL query
Add
@google-cloud/bigquerynpm package topackage.json
This article assumes that you already have a Google developer account
If not just create a new one and then go to IAM in the web console and create a service account with BigQuery Admin permission. Donwload the JSON file and save it to our application folder. Worth adding to .gitignore and never commit.
Our package.json will look like that:
{
"name": "js-lambda-unit-tests",
"version": "1.0.0",
"description": "Simple micro service with unit tests.",
"main": "app.js",
"scripts": {
"local": "export DEBUG=true; export NODE_ENV=staging; run-local-lambda --file app.js --event test/event.json --timeout 1",
"test-lambda-runtime": "NODE_ENV=test mocha --timeout 10000 ./test/unit/runTimeTest.js",
"test-lambda-response": "NODE_ENV=test mocha --timeout 10000 ./test/unit/lambdaResponseTest.js",
"test-unit": "NODE_ENV=test mocha NODE_ENV=test --exit --recursive ./test/unit",
"test-integration": "NODE_ENV=test mocha --require ./test/fixtures/bigquery-integration-bootstrap.js --timeout 100000 ./test/integration/simpleTest.js"
},
"author": "",
"license": "ISC",
"devDependencies": {
"aws-sdk": "2.804.0",
"run-local-lambda": "1.1.1",
"eslint": "^7.20.0",
"eslint-plugin-classes": "^0.1.1",
"eslint-plugin-promise": "^4.3.1",
"mocha": "^7.1.1",
"chai": "^4.2.0"
},
"dependencies": {
"moment": "^2.24.0",
"@google-cloud/bigquery": "^5.12.0"
}
}
So next time when we run npm run test-integration it will run the test we need.
Now let's add an async function to execute SQL in BigQuery:
const executeQuery = async(sql) => {
const options = {
query: sql,
location: 'US',
};
const [job] = await bigquery.createQueryJob(options);
console.log(`Job ${job.id} started.`);
const [rows] = await job.getQueryResults();
if (rows.length === 0) {
return null;
}
return rows;
};
Add it in our app.js somewhere at the bottom. Although it will be better to move it to a separate module it will do just fine for now. So our final app.js will look this:
...
const processEvent = async(jobs) => {
const now = moment.utc();
const jobList = [];
for (const job of jobs) {
try {
if (typeof job.name === 'undefined') {
throw { errorCode: 1, message: 'job.name is missing' };
}
const jobTime = now.format('YYYY-MM-DD HH:mm');
const bigQueryData = executeQuery('SELECT 1 as id;');
jobList.push({
name: job.name,
runTime: jobTime,
data: bigQueryData,
});
} catch (error) {
return error;
}
}
return jobList;
};
const executeQuery = async(sql) => {
const options = {
query: sql,
location: 'US',
};
const [job] = await bigquery.createQueryJob(options);
console.log(`Job ${job.id} started.`);
const [rows] = await job.getQueryResults();
if (rows.length === 0) {
return null;
}
return rows.map((row) => row.id);;
};
In the end, we would expect some data from BigQuery to be added to the processing results of our app.js
Now we need one more thing.
We would want to isolate our data environment used for integration tests from what we have in production. There are different approaches and we can either use separate datasets (production, tests) or use separate BigQuery projects, i.e. data-production and data-tests. A free GCP account allows to use of two projects so I went for option number two.
Add BigQuery project for tests
We can create it from the Google Cloud web console. The whole thing won't take more than 5 minutes. Now we need to add our main BigQuery project service account email to a list of users with BigQuery Admin permission for this new account. We will use it to authenticate our application with this new project too.
To tell our app.js which project to use we will use environment variables and npm config. We also need npm i js-yaml as config would require that dependency later. We can install it as easily as running npm run i config and all we need to do now is to create a ./config folder where we will keep our configuration files:
.
├── default.yaml
├── production.yaml
├── staging.yaml
└── test.yaml
So depending on where we choose to deploy our service (environment wise) it will define the variables for our app.js
For example, test.yaml using our service account credentials from production BigQuery project will be able to access data-tests project and run queries there:
bigQuery:
projectId: data-tests
jobs:
-
name: extractFromWildcardTable
schedule: '30 02 * * ? *'
We will authenticate our aap.js by adding these lines to our code:
const NODE_ENV = process.env.NODE_ENV || 'tests';
const TESTING = process.env.TESTING || 'true';
const config = require('config');
const moment = require('moment');
const { BigQuery } = require('@google-cloud/bigquery');
// Constants
const bigQueryCreds = require('./bigquery.json'); // Never commit this file, use KMS or any other secret manager provider.
...
...
const bigquery = new BigQuery({
projectId: config.get('bigQuery.projectId'),
credentials: {
client_email: config.gcp.gcpClientEmail,
private_key: bigQueryCreds.private_key,
},
});
So now when we run npm run test-integration from the command line it will use settings from ./config/test.yaml
Integration bootstrap
One final thing to consider though. We might want to run some pre-test code before we run the actual integration test. You probably already noticed it in package.json scripts:
...
"test-integration": "NODE_ENV=test mocha --require ./test/fixtures/bigquery-integration-bootstrap.js --timeout 100000 ./test/integration/simpleTest.js"
...
In my case, it will be this simple code (for demonstration purposes) ./test/fixtures/bigquery-integration-bootstrap.js
const DEBUG = process.env.DEBUG || 'true';
const NODE_ENV = process.env.NODE_ENV || 'test';
const TESTING = process.env.TESTING || 'true';
const config = require('config');
const bigQueryCreds = require('../../bigquery.json');
const { BigQuery } = require('@google-cloud/bigquery');
// // Test datasets
// const build = require('./buildTestDatasets.sql.js');
// const truncate = require('./cleanupTestDatasets.sql.js');
// const buildDatasets = async() => {
// for (const table in build) {
// console.log(`Loading test data into ${config.get('bigQuery.projectId')}:${table}`);
// await executeQuery(build[table]);
// }
// }
// ;
// const cleanupDatasets = async() => {
// for (const table in truncate) {
// console.log(`Truncating test table ${config.get('bigQuery.projectId')}:${table}`);
// await executeQuery(truncate[table]);
// }
// }
// ;
// Variables
const bigquery = new BigQuery({
projectId: config.get('bigQuery.projectId'),
credentials: {
client_email: config.gcp.gcpClientEmail,
private_key: bigQueryCreds.private_key,
},
});
// Constants
const CLEANUP_TIMEOUT = 50000;
async function executeQuery(sql) {
const options = {
query: sql,
location: 'US',
};
const [job] = await bigquery.createQueryJob(options);
console.log(`Job ${job.id} started.`);
const [rows] = await job.getQueryResults();
if (rows.length === 0) {
return null;
}
return rows;
}
(async() => {
try {
console.log('creating test datasets in data-tests project');
// await buildDatasets();
run();
} catch (err) {
console.log('Problem creating test data in BigQuery: ', err);
// cleanupDatasets();
}
}
)();
process.on('SIGINT', () => {
console.log('Caught interrupt signal');
cleanupDatasets();
});
That's pretty much everything. Now we just need to create the Integration test itself.
Integration test
Again this is going to be a very simple test with Mocha and Chai. We would expect that id returned by BigQuery (using SELECT 1 as id query) equals 1.
...
it('should return a 200 statusCode and array [] of jobs each having a data key equals array of [1]', async() => {
const event = { 'configOverride': true,
'jobs': [
{
'name': 'get_bigquery_data',
'output': 's3',
'dryRun': false,
'disabled': false,
},
],
};
const response = await app.handler(event);
console.log(response);
expect(response).to.have.property('statusCode');
expect(response.statusCode).to.be.deep.equal(200);
expect((response.data).length).to.equal(1);
expect((response.data)[0]).to.have.keys('data', 'runTime', 'name');
expect((response.data)[0].data).to.be.equal('1');
});
...
Here we go:
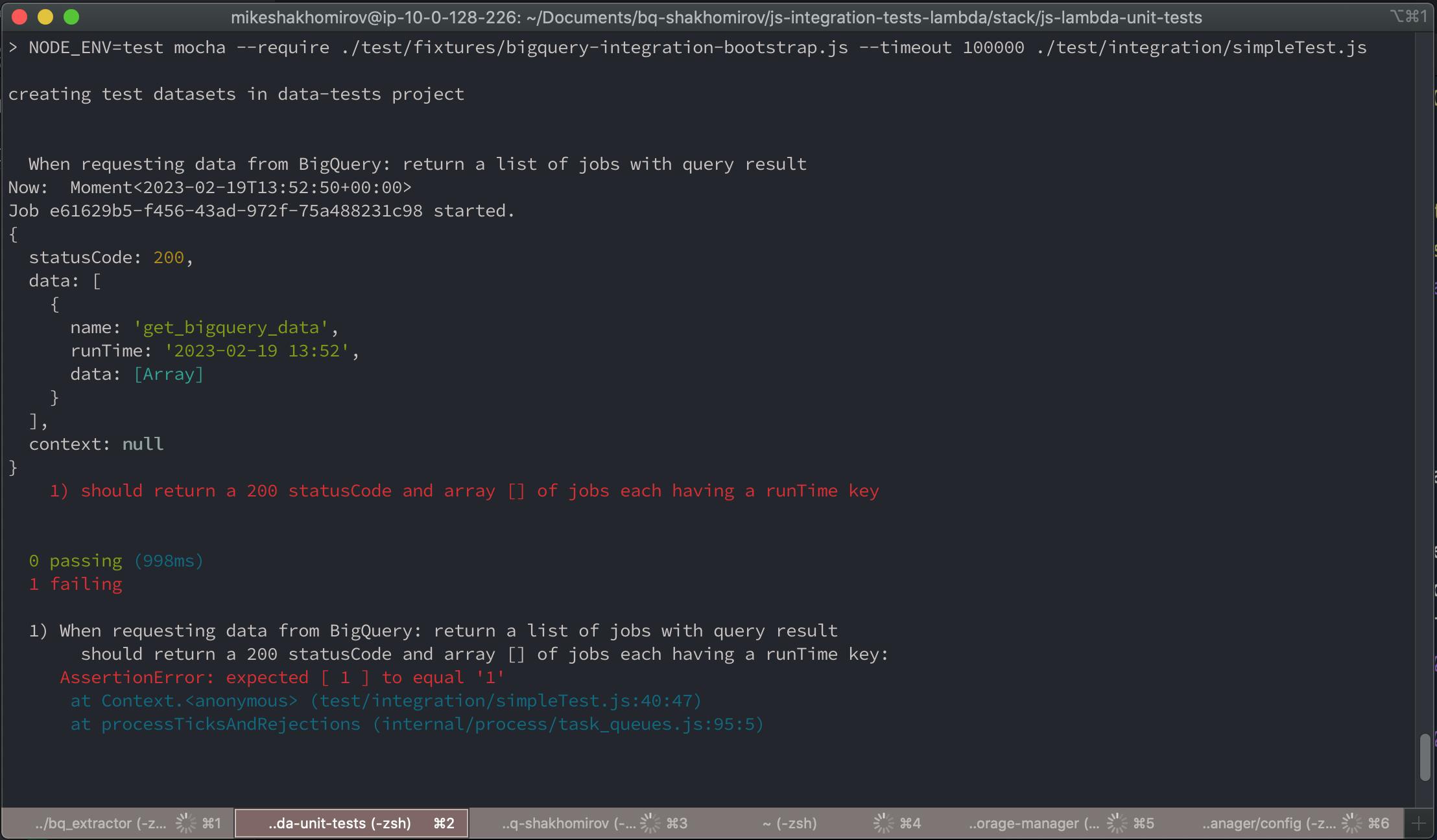
It is failing due to the wrong format. we expect STRING bur returned is a number. Let's change this in our integration test:
//expect((response.data)[0].data).to.be.equal('1');
expect((response.data)[0].data).to.be.deep.equal([1]);
Now it runs fine:
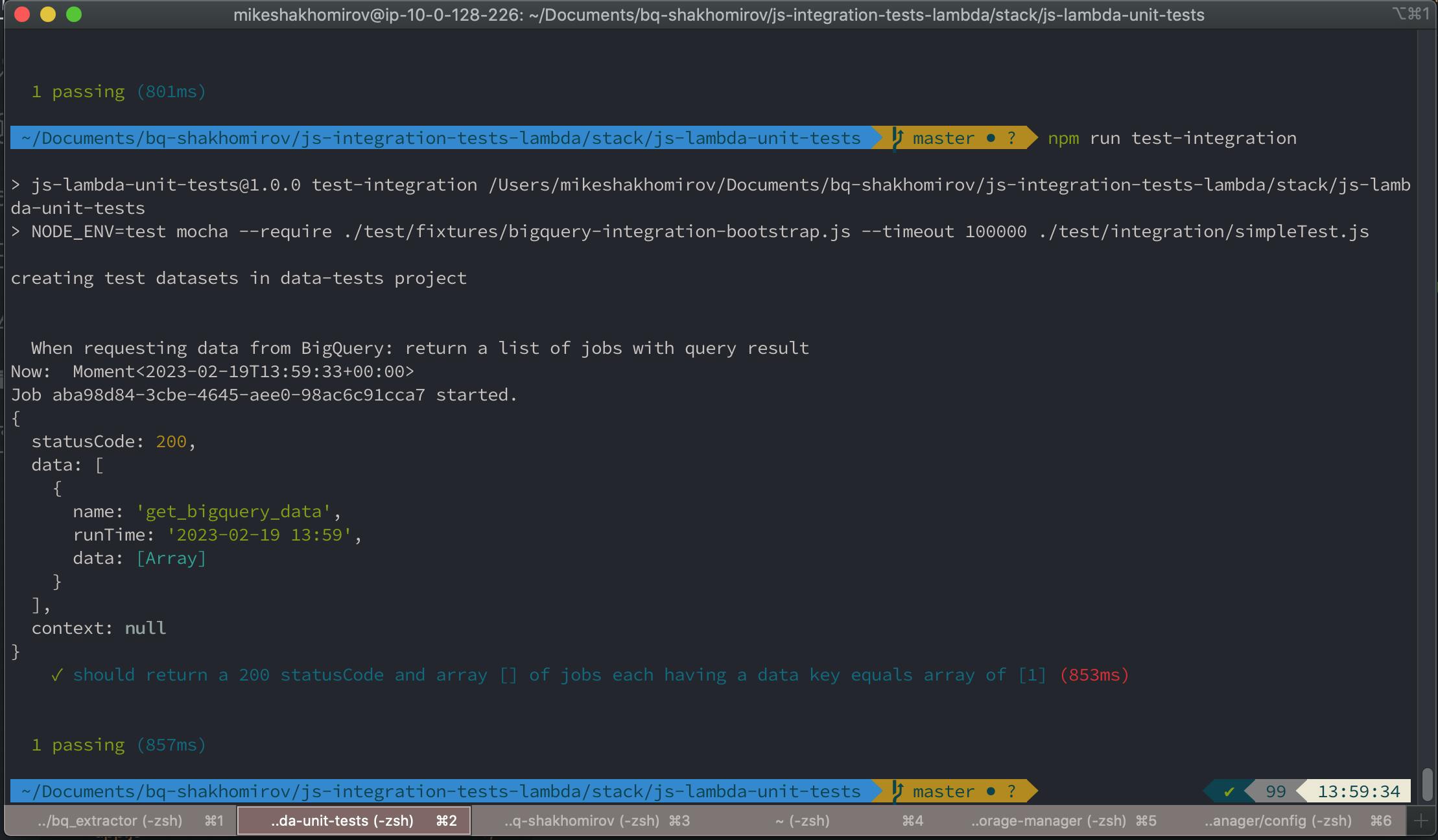
Conclusion
AWS Lambda is a powerful tool that can be used to manage and orchestrate data pipelines. Integration testing simplifies deployment and speeds up development. We have just created a template microservice to do that and run tests. In a similar way, we can test integration with any other API. It can be something internally deployed in your VPC or externally like the BigQuery example above.
We can deploy it with Infrastructure as code and reproduce it as many times as we want in any environment or cloud account.
https://medium.com/gitconnected/infrastructure-as-code-for-beginners-a4e36c805316
Unit tests are important. Testing skills are crucial for dev teams and it looks great on your CV.
Repository
https://github.com/mshakhomirov/js-integration-tests-lambda
Recommended read:
https://www.chaijs.com/api/bdd/
https://stackoverflow.com/questions/52019039/how-to-test-aws-lambda-handler-locally-using-nodejs
https://stackoverflow.com/questions/54846513/lambda-trigger-callback-vs-context-done
http://opensourceforgeeks.blogspot.com/2019/03/writing-unit-tests-for-aws-lambda-in.html